
In this post I will try to make understandable a Deep Neural Network I developed lately. We are still in early stages and a lot of improvements will need to get in, but the preliminary results are positive. I have been told I am not so great at explaining things high level, so a word of warning, some part may go deep technical! So, let start with the buzz words: what I will describe is a One-Shot Learning approach using a Siamese Deep Neural Network which characterize ongoing data traffic patterns in a telecom network to identify faults in real-time.
Telecom network nodes (think piece of equipment) often suffer from recurring faults. There are things which are done by human operator, or traffic pattern exhibited by the users, or situations in adjacent nodes which can impact the performance of a specific node. Once degradation is identified, an analyst goes through the alarms raised by the equipment or the logs, figure out the issue and fix it. Some of those faults are recurring for a reason or another. Analysts probably gets better and better at identifying and fixing those, but still it takes some of their precious time. Would not it be nice if we could identify those automatically and then act to fix the problem? This is pretty much in line with the ONAP vision of a complete life-cycle management of a service. Let say it is a small part of the mechanism required to make that vision real.
The objective is to develop a Machine Learning trained analytic module for a specific set of Network Function Virtualization (NFV) components which can feed into the ONAP policy engine architecture. The analytic module monitors in real-time the NFV service levels and informs the policy engine about the NFV service status i.e. normal working status or degraded/failure mode and in such a case why it is failing.
Ideally, we want a trained analytic module which knows about a lot of different errors characteristics and can adapt as easily as possible to different network conditions i.e. nodes in different networks may be subject to different traffic patterns, but still be subjected to the same errors. In other terms, it would be nice to be able to deploy this module to supervise nodes deployed at different operators without having to retrain it completely…
For the purpose of this experiment we use as data traffic information collected by probes on the control plane traffic coming into/out of a specific node (P-CSCF (a Proxy Server) of an IP Multimedia Subsystem (IMS)). The probes are part of an Ericsson product, the Ericsson Expert Analytics and takes care of the collection and storage of the data from the NFV component. The P-CSCF is part of a test network we created for the experiment and is subject to a realistic traffic model simulated by network traffic generation servers.
The first step is to characterize statistically the traffic going through the P-CSCF and collected by the probes. In this step we create a set of about 130 statistical features based on 1 minute intervals describing the traffic. For example: Number of Registrations in a minute; Number of Session Initiations; Number of operations presenting error codes and count of those error codes e.g. number of Registrations with return code 2xx, 3xx, … ; Average time required to complete operations; Standard Deviation of those times; etc.
A first choice is how long of a stream should be base our decision on? We decided to go with 1-hour intervals thus we use 60 consecutive examples of those 130 or so features vector for training and for predictions. We label our examples such that if for the whole period there is no error present it is “normal traffic”, or if we introduced an error during that 60 minutes period, thus the example exhibits in part a specific error then it is labelled as per this error.
To fulfil our need for easy adaptation of the trained analytic module we decided to go with One-Shot learning approach. Our hope is that we can train a Deep Neural Network which characterize the traffic it is presented with on a “small” vector (here we initially selected a vector of 10 values), akin to words embedding in Natural Language Processing (NLP). We also hope then that vector arithmetic properties observed in that field for translation purpose will hold e.g. king – man + woman = queen; paris – france + Poland = warsaw. If such property hold, deployment of the trained analytic module in a different environment will consist simply in observing a few examples of regular traffic and adjusting to the specific traffic pattern through arithmetic operations. But I am getting ahead of myself here!
To perform training according to One-Shot learning strategy we developed a base LSTM-based Deep Neural Network (DNN) which is trained in a Siamese Network framework akin what is done for Image Recognition. To do so we create triplets of Anchor-Positive-Negative of 60 minutes/130 features data. In other words, we select an anchor label e.g. normal traffic, or error X, we then select a second example of the same category and a third example from another label category. This triplet of examples becomes what we provide as examples to our Siamese framework to train our LSTM-based DNN. Our initial results were obtained with as little as 100k triplets thus we expect better results when we will train with more examples.
Our Siamese framework can be described as following: The three data points from a triplet are evaluated through the base LSTM-based DNN and our loss function see to minimize the distance between Anchor-Positive examples and maximize the distance between Anchor-Negative examples. The base LSTM-based DNN is highly inspired from my precious trial with time-series and consist in the following:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= batch_normalization_1 (Batch (None, 60, 132) 528 _________________________________________________________________ lstm_1 (LSTM) (None, 60, 512) 1320960 _________________________________________________________________ lstm_2 (LSTM) (None, 512) 2099200 _________________________________________________________________ batch_normalization_2 (Batch (None, 512) 2048 _________________________________________________________________ dense_1 (Dense) (None, 512) 262656 _________________________________________________________________ batch_normalization_3 (Batch (None, 512) 2048 _________________________________________________________________ dense_2 (Dense) (None, 10) 5130 _________________________________________________________________ batch_normalization_4 (Batch (None, 10) 40 ================================================================= Total params: 3,692,610 Trainable params: 3,690,278 Non-trainable params: 2,332 _________________________________________________________________
Once the base LSTM-based DNN is trained, we can compute the vector representation of each of the traffic case we are interested in e.g. Normal Traffic, Error X traffic, … and store them.
When we want to evaluate real-time the status of the node, we pick the last hour of traffic data and compute its vector representation through the trained base LSTM-based DNN. The closest match from the stored vector representation of the traffic cases and the current traffic is our predicted current traffic state.
At this point in time we only data collected for one specific error, where a link between the P-CSCF and the Home Subscriber Server (HSS) is down. Below diagram shows our predictions on a previously unseen validation set i.e. not used for training.
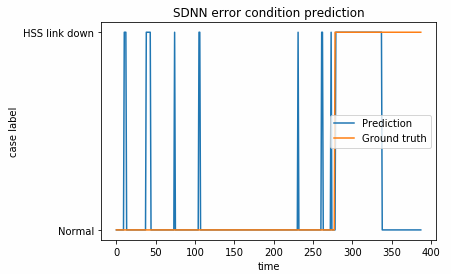
As we can see there is quite a few small false predictions along the way, but when the real error is presented to the trained model it can identify it correctly.
Our next steps will be to collect data for other errors and train our model accordingly. As I said in the beginning this is quite early results but promising nonetheless. So keep tuned-in for more in the new year!

Reblogged this on Qamar-ud-Din.
LikeLike
How are you training your model? And wouldn’t using a public provider for compute be a violation of some kind of internal policy?
LikeLike
It was trained on an internal GPU server we had to specify, source and get installed, so a whole adventure in itself! We were to re-use it, so the adventure was worth it.
LikeLike
Do you train the model using only 100k triplets? The parameters of NN is 3 million, and it should be overfitting, doesn’t it?
LikeLike
Initially we would have a lot less examples, but as it started to show promises the triplets were picked automatically from the pool of data we had and we could provide a lot more triplets than that. But to be honest this is now kind of far away in my memory and I don’t have access to that code anymore.
LikeLike